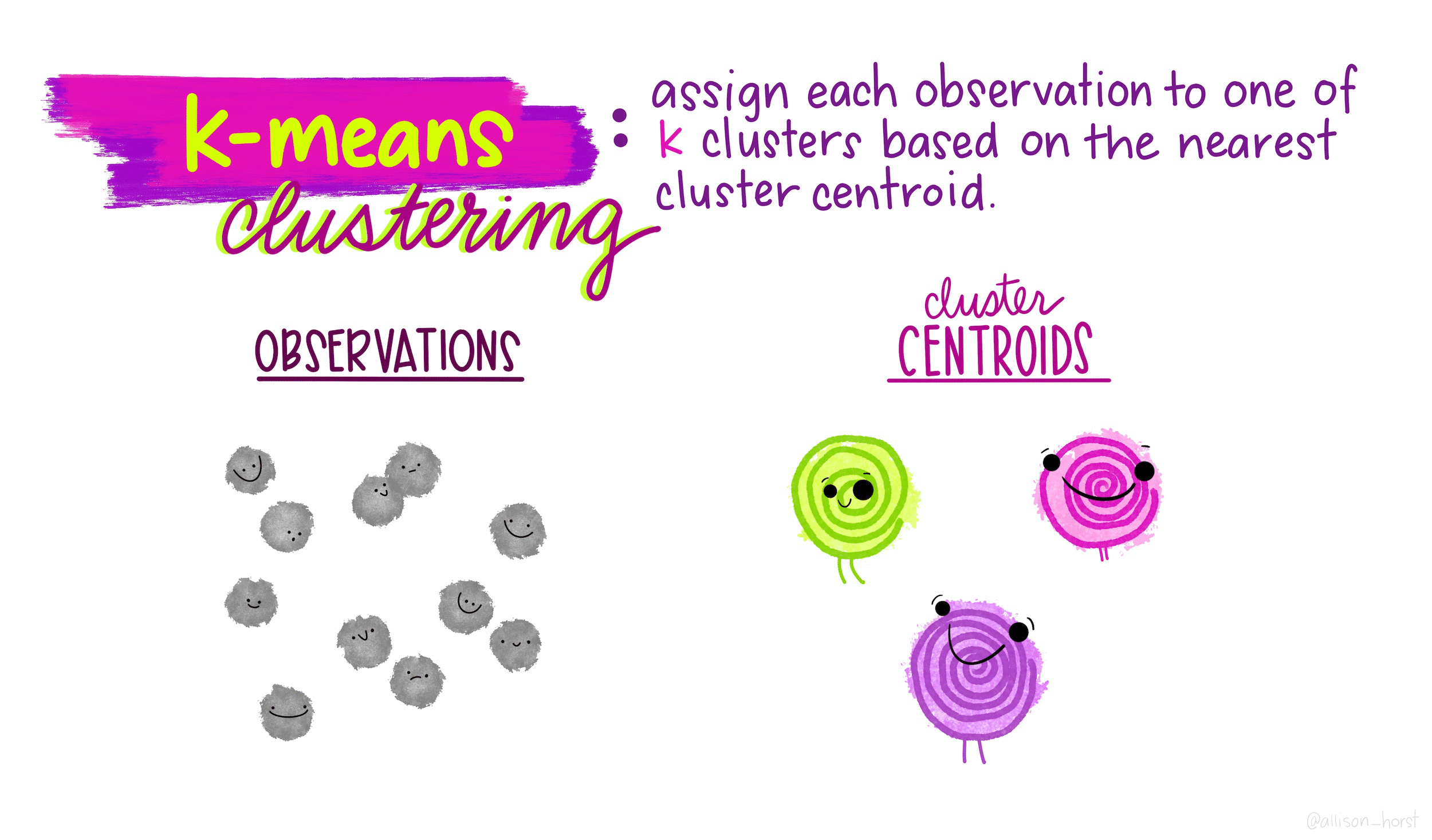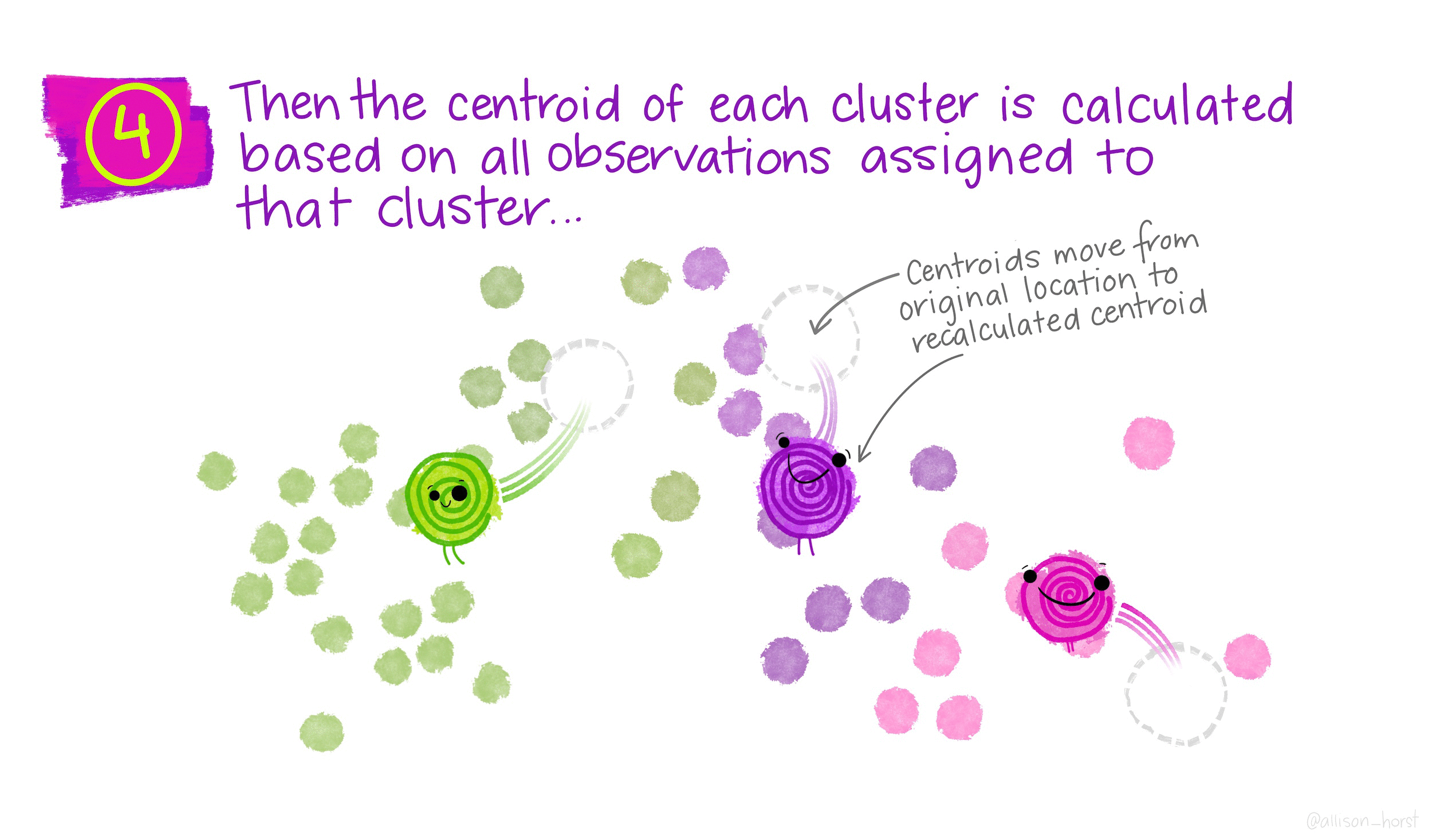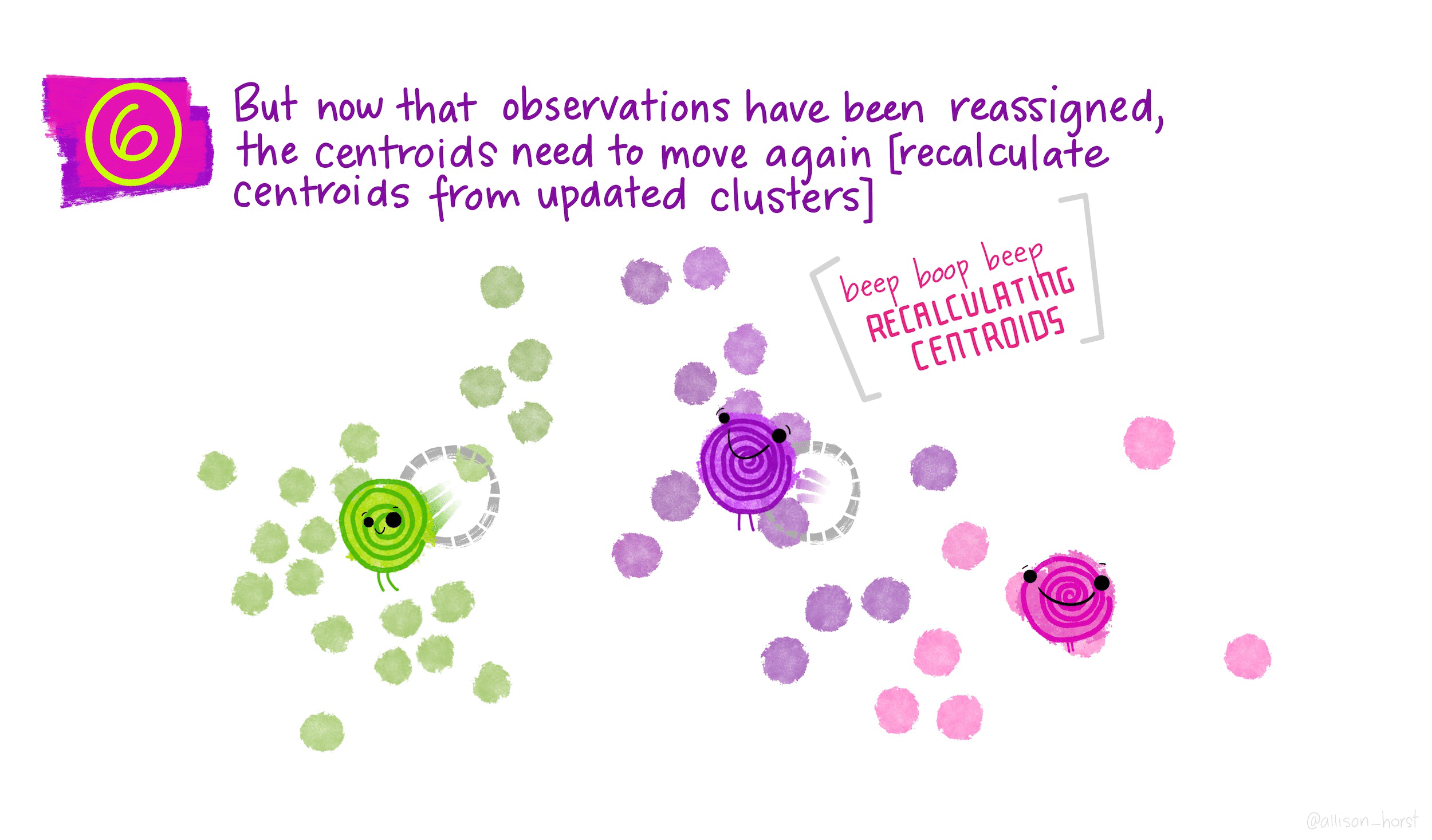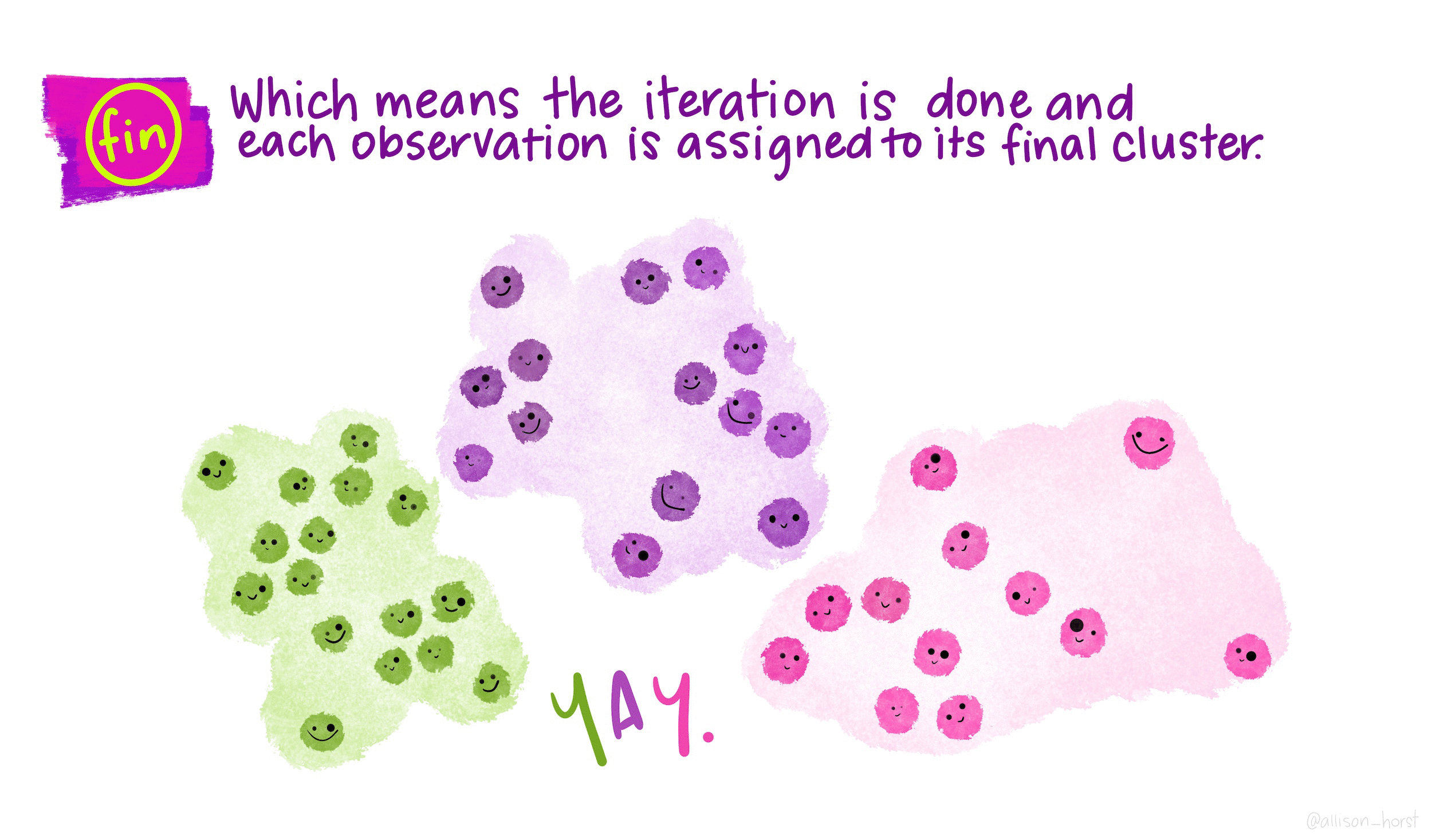
K-Means Clustering : K-means Clustering - Sehwa Na - Medium : When we cluster observations, we want observations in the same.. We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. When we cluster observations, we want observations in the same. Algorithm, applications, evaluation methods, and drawbacks. Precisely, machine learning algorithms are broadly categorized as. It follows a simple procedure of classifying a given data set into a number of clusters.
Given a finite set of data points. It follows a simple procedure of classifying a given data set into a number of clusters. The goal of this algorithm is to find groups in the data. Algorithm, applications, evaluation methods, and drawbacks. A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster.
Learn - K-means clustering with tidy data principles from www.tidymodels.org The goal of this algorithm is to find groups in the data. When we cluster observations, we want observations in the same. Here, k represents the number of clusters and must be provided by. Given a finite set of data points. Precisely, machine learning algorithms are broadly categorized as. We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. It follows a simple procedure of classifying a given data set into a number of clusters. A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster.
A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster.
We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. The goal of this algorithm is to find groups in the data. Algorithm, applications, evaluation methods, and drawbacks. When we cluster observations, we want observations in the same. Clustering is a broad set of techniques for finding subgroups of observations within a data set. A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster. While machine learning is often thought of as a fairly new concept, the fundamentals have been around for much longer than. It follows a simple procedure of classifying a given data set into a number of clusters. Precisely, machine learning algorithms are broadly categorized as. Given a finite set of data points. Here, k represents the number of clusters and must be provided by.
A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster. Algorithm, applications, evaluation methods, and drawbacks. It follows a simple procedure of classifying a given data set into a number of clusters. Given a finite set of data points. Clustering is a broad set of techniques for finding subgroups of observations within a data set.
K-means clustering | Polymatheia from sherrytowers.com Here, k represents the number of clusters and must be provided by. Given a finite set of data points. When we cluster observations, we want observations in the same. Clustering is a broad set of techniques for finding subgroups of observations within a data set. We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. It follows a simple procedure of classifying a given data set into a number of clusters. While machine learning is often thought of as a fairly new concept, the fundamentals have been around for much longer than. A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster.
We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items.
We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. Here, k represents the number of clusters and must be provided by. A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster. Precisely, machine learning algorithms are broadly categorized as. It follows a simple procedure of classifying a given data set into a number of clusters. The goal of this algorithm is to find groups in the data. Given a finite set of data points. When we cluster observations, we want observations in the same. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Algorithm, applications, evaluation methods, and drawbacks. While machine learning is often thought of as a fairly new concept, the fundamentals have been around for much longer than.
Here, k represents the number of clusters and must be provided by. Clustering is a broad set of techniques for finding subgroups of observations within a data set. We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. Precisely, machine learning algorithms are broadly categorized as. It follows a simple procedure of classifying a given data set into a number of clusters.
Implementing K-means clustering in Python from Scratch ... from i2.wp.com Here, k represents the number of clusters and must be provided by. While machine learning is often thought of as a fairly new concept, the fundamentals have been around for much longer than. It follows a simple procedure of classifying a given data set into a number of clusters. Algorithm, applications, evaluation methods, and drawbacks. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Given a finite set of data points. The goal of this algorithm is to find groups in the data. When we cluster observations, we want observations in the same.
Precisely, machine learning algorithms are broadly categorized as.
A very common example of an unsupervised machine learning, clustering is the process of grouping similar data points into a cluster. When we cluster observations, we want observations in the same. Algorithm, applications, evaluation methods, and drawbacks. We categorize each item to its closest mean and we update the mean's coordinates, which are the averages of the items. While machine learning is often thought of as a fairly new concept, the fundamentals have been around for much longer than. Given a finite set of data points. Clustering is a broad set of techniques for finding subgroups of observations within a data set. Here, k represents the number of clusters and must be provided by. The goal of this algorithm is to find groups in the data. Precisely, machine learning algorithms are broadly categorized as. It follows a simple procedure of classifying a given data set into a number of clusters.

{kind=link}